Amazon Transcribe で日本語音声ファイルをテキスト化してみる
Amazon Transcribe を使うと「音声ファイル → テキスト」へ変換することが出来ます。 この Transcribe が日本語対応したので試してみました。
サンプル¶
今回は下記にある音声サンプルファイルを利用させて頂きました (「視聴頂けます」の記載はあるものの、二次利用に関する言及が無かったので「使って良いのか?」心配ですが…)
注意点¶
入力オーディオファイルは S3 Bucket 上に配置済みの想定です。 但し、「Transcribe Job と S3 Bucket のリージョンが一致していないとエラーになる」点には注意します。 S3 Bucket へ特殊な設定は不要です。
Step.1¶
AWS 管理コンソールから Amazon Transcribe へアクセスします。 トップページが表示されたら Create transcription job をクリックします。
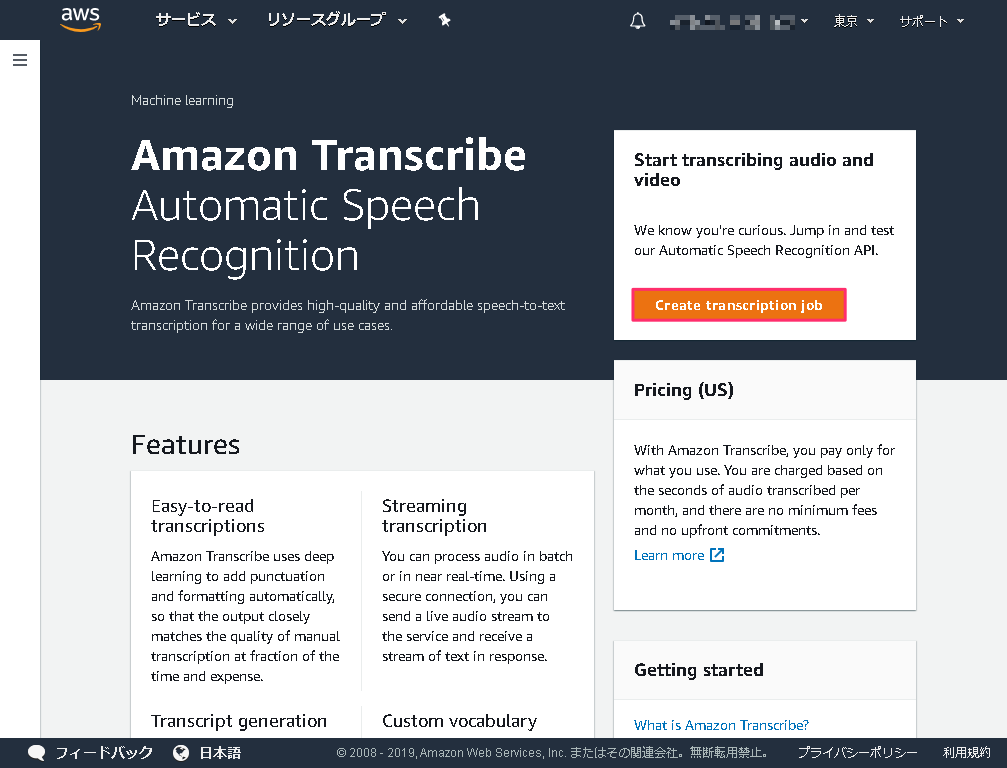
Step.2¶
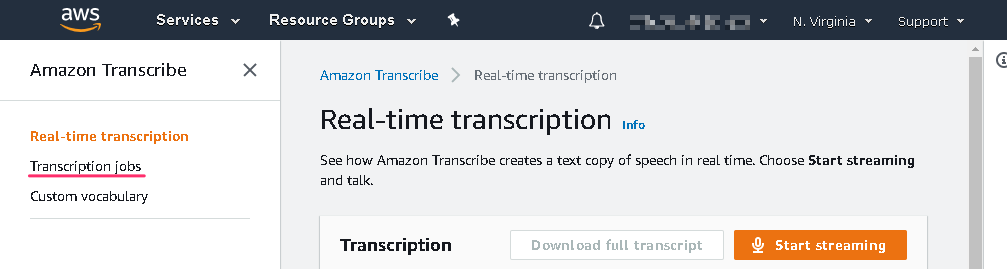
Real-time transcription に対応しているリージョンで操作していると、トップの次に下記画面へ遷移するようです。 この場合は左側のナビゲーションから Transcription jobs をクリックして次へ進みます (現時点の東京リージョンでは Real-time transcription に対応しておらず、この画面には遷移しないようです)。
Step.3¶
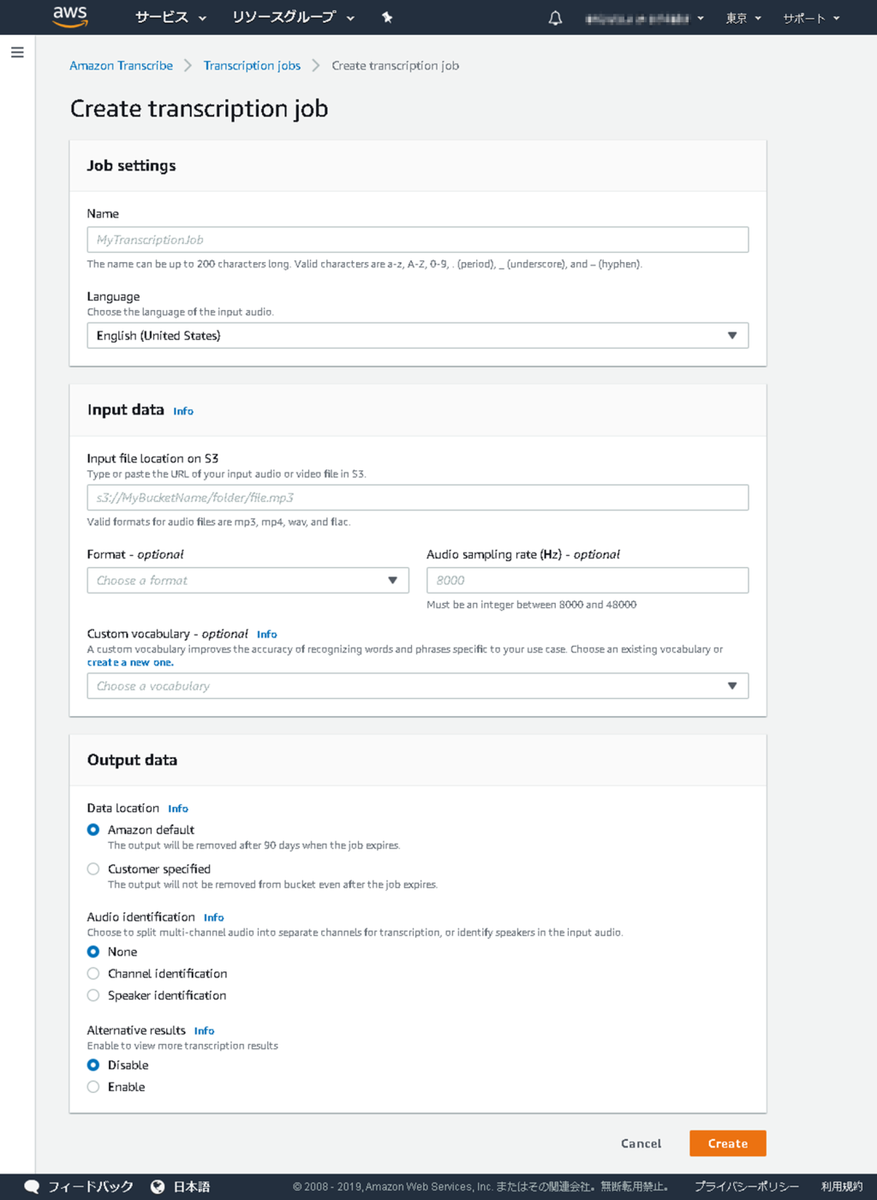
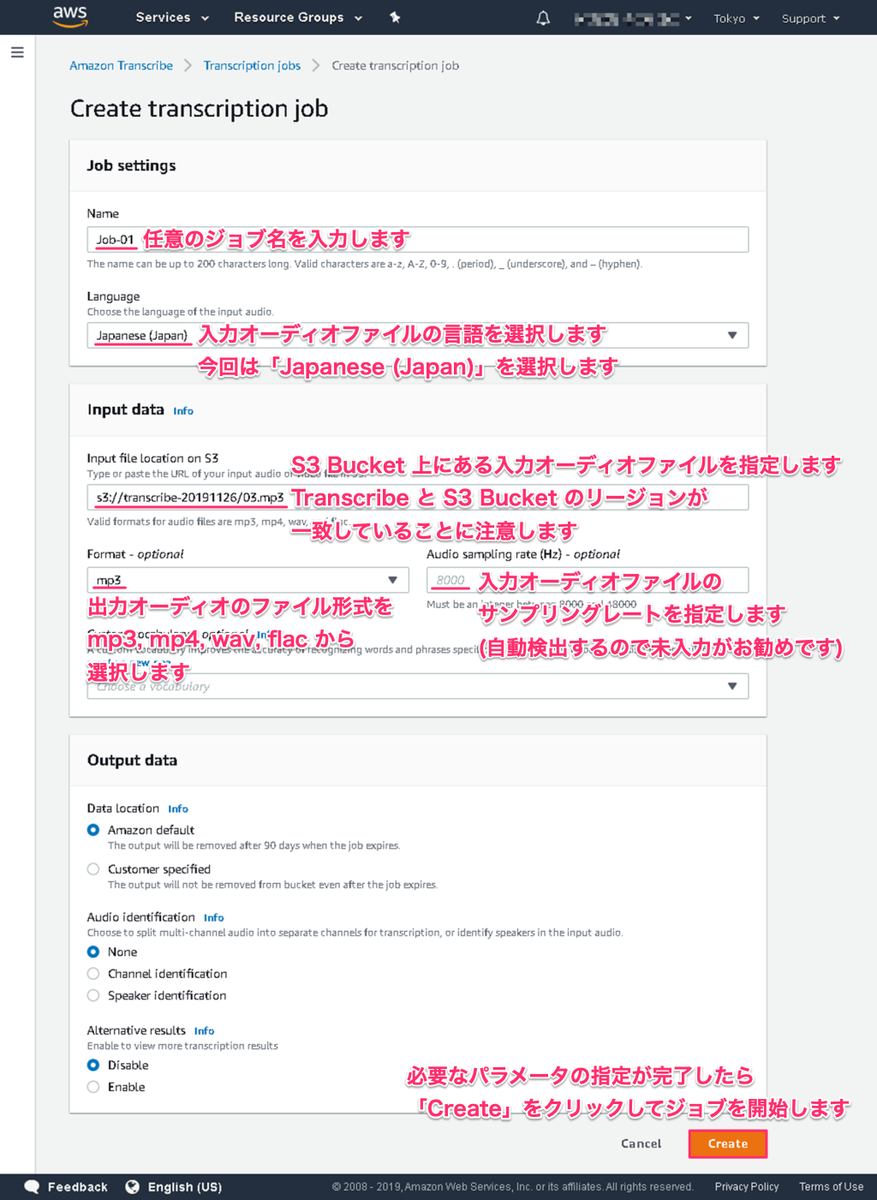
以下のような画面に遷移します。 これから必要なパラメータを入力していきます。
Step.4¶
以下のようにパラメータを入力します。 入力が終わったら画面右下の Create をクリックして次へ進みます。
| 項目 | 必須 | 値 |
|---|---|---|
| Name | 必須 | このジョブに設定する任意の名称を入力します |
| Language | 必須 | 入力オーディオファイルの言語を指定します。 今回は日本語の音声ファイルを扱う為、「Japanese (Japan)」を選択します |
| Input file location on S3 | 必須 | S3 上にある入力オーディオファイルのパスを入力します |
| Format | 入力オーディオファイルの形式を mp3, mp4, wav, flac から選択します。 入力を省略すると自動判別される為、通常は空欄で良いと思います | |
| Audio sampling rate (Hz) | 入力オーディオファイルのサンプリングレートを入力します。 誤った値を指定するとエラーになってしまう為、敢えて入力せず、自動検出させるのがお勧めです |
Step.5¶
S3 Bucket と Transcribe Job のリージョンが不一致な場合、以下のエラーになります。 S3 Bucket か、または Transcribe Job のリージョンを修正して、両者が一致するようにします。

Step.6¶
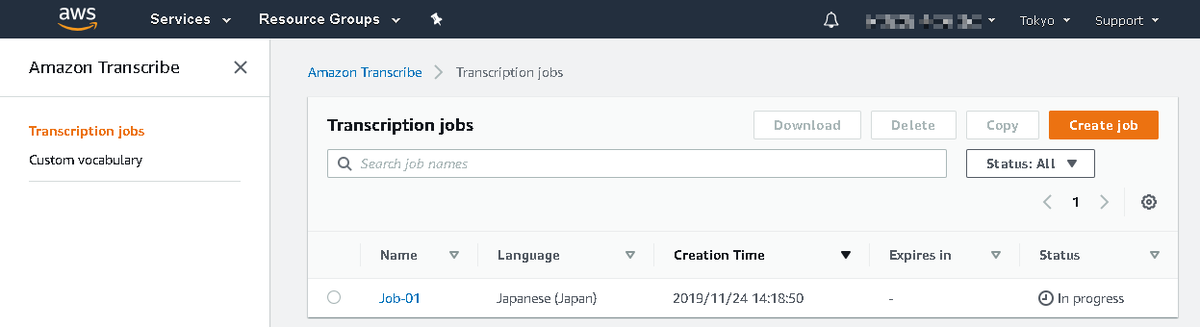
エラーが無ければ以下の画面へ遷移します。 対象 Job の Status が In progress になっており、処理中であることが分かります。 処理にかかる時間は入力オーディオファイルの長さ次第です。
Step.7¶
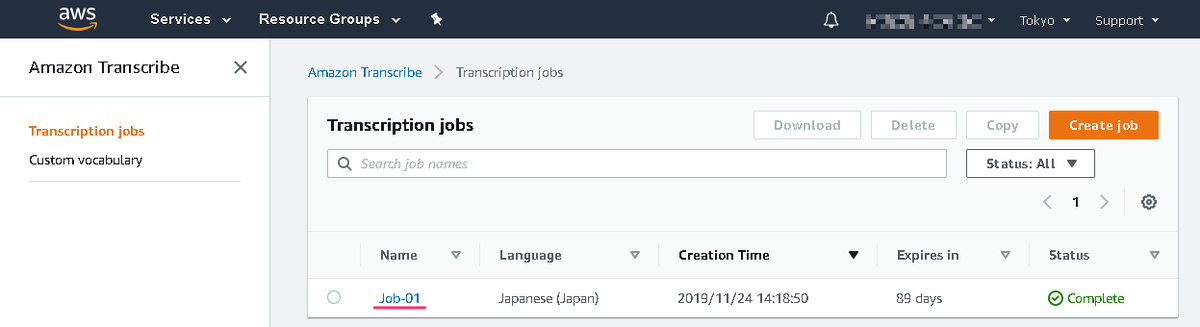
しばらく待つと Sttaus が Complete になり、処理が完了します。 結果を確認する為、Job 名をクリックします。
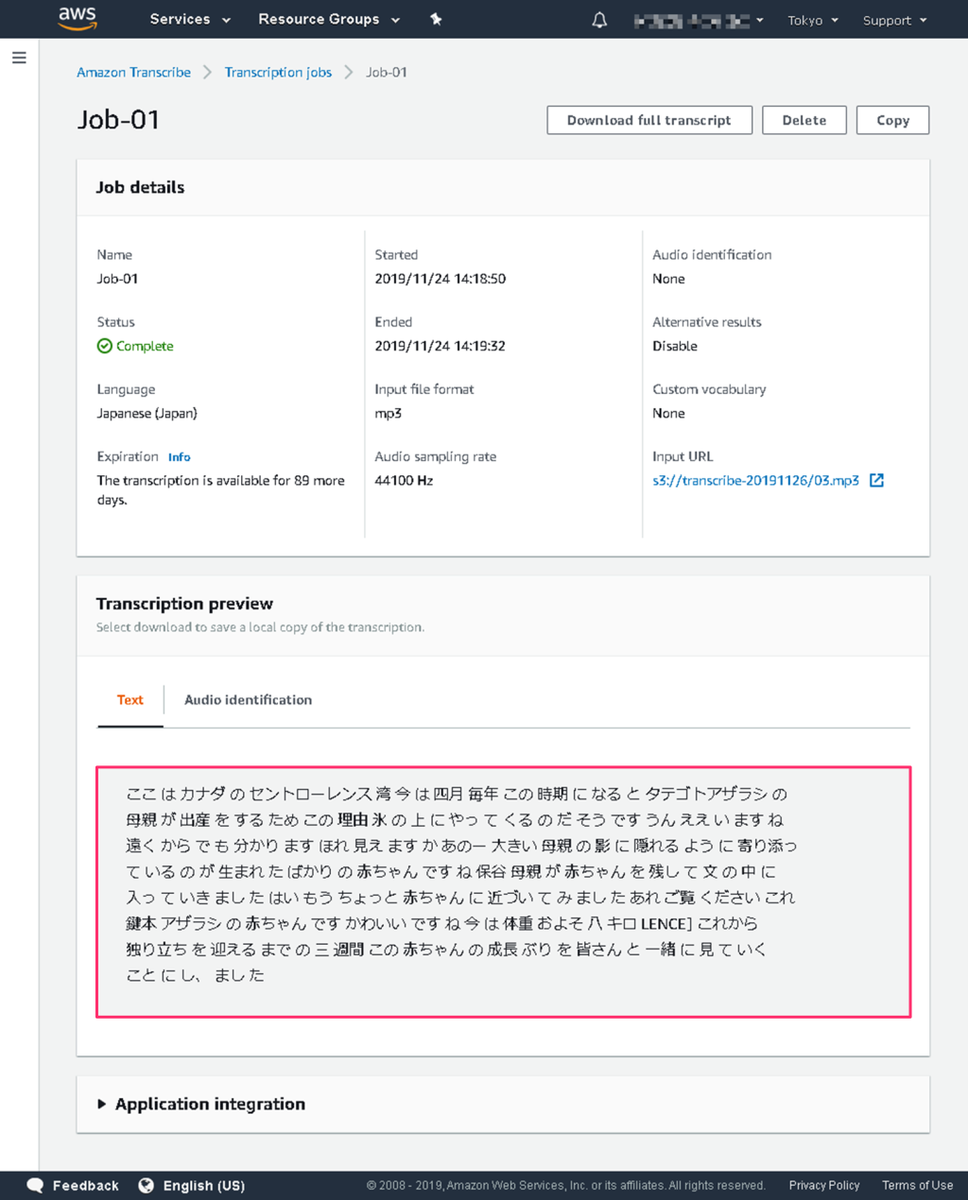
Step.8¶
以下のような画面になり、結果 (音声ファイルに基づいて作成されたテキスト) が表示されます。